
I’d previously employed this technique for sidestepping expired content SEO considerations, but I think there are further applications.
Expired Content SEO (Oversimplified)
We know that irrelevant redirects are unlikely to pass value from the origin URL to the destination. This is why most of the methods around redirecting expired content seem to have a significant “hope” factor:
- Update content.
- Let it die (404).
- Redirect it to the homepage and hope.
- Redirect it to something sort of relevant and hope.
- Keep the page live, avoid soft-404 detection.
Like most of my ideas, this application leans on standard techniques we already have at our disposal, applied in a counter-intuitive manner:
You can launder irrelevant content by turning it into duplicate content.
One of the main methods of handling duplicate content is by declaring a canonical version using the canonical link element.
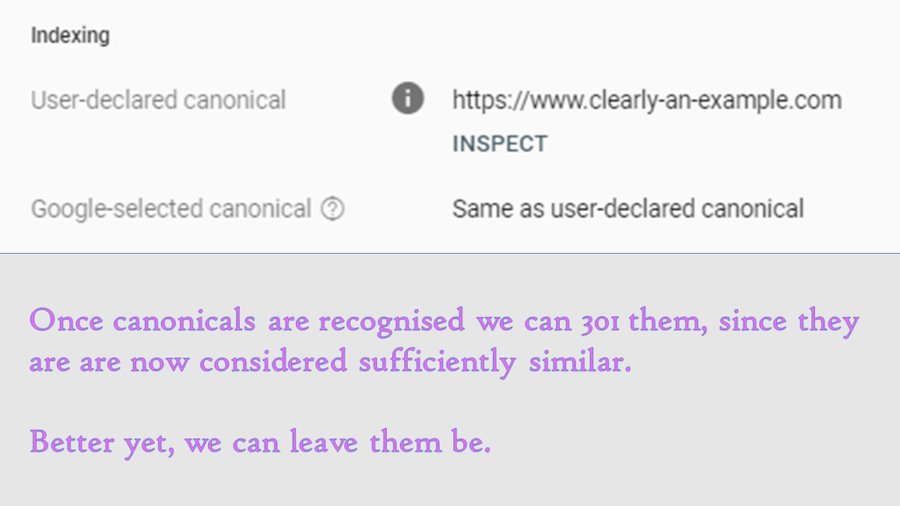
Once accepted, canonical relationships reliably transfer ranking signals. And we can know when canonical relationships have been accepted by using Search Console:
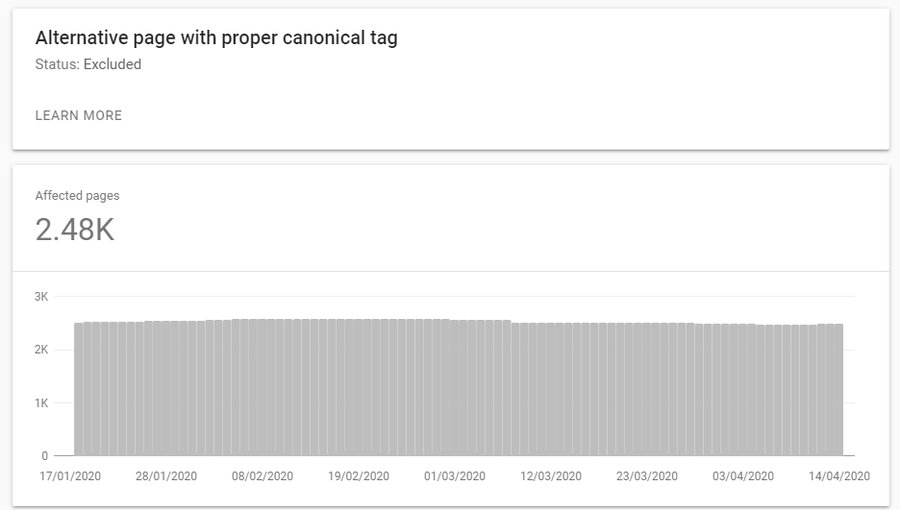

It’s likely that there are already self-referencing canonicals in use on the destination page you have in mind. If so, you can literally duplicate the destination content on the origin URL, so that /irrelevant-origin-url displays the content of /desired-destination
Once a canonical is clearly and consistently being respected, you can probably get away with 301 redirecting it. But why?
The appeal of this technique is that it is not limited in scope. You can lend the strength of any page to any other more reliably than with any other technique I know.
Where it is an absolute bastard and is completely unworkable is that nobody will want to manage this. Nobody.
You might think “Oliver, this is a shit idea”. You’d be right.
Example Implementation
I’m going to take you step-by-step through an example on my own website, in this instance an out of date post I wrote in 2013 about knowing when a canonical link is being obeyed (https://ohgm.co.uk/know-when-a-canonical-is-obeyed/):
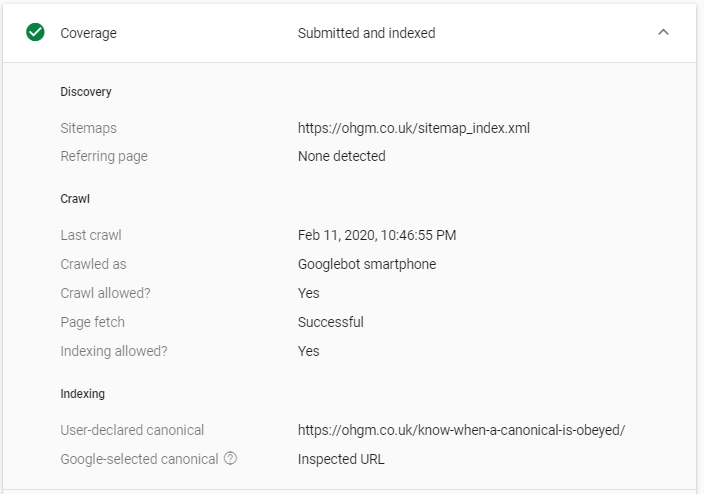
If we inspect the URL in Search Console we can see that it’s currently indexed and refers to itself:
So now I’m returning my desired, truly unrelated content (in this case the ohgmcon HTML ‘/con/’) on this URL:
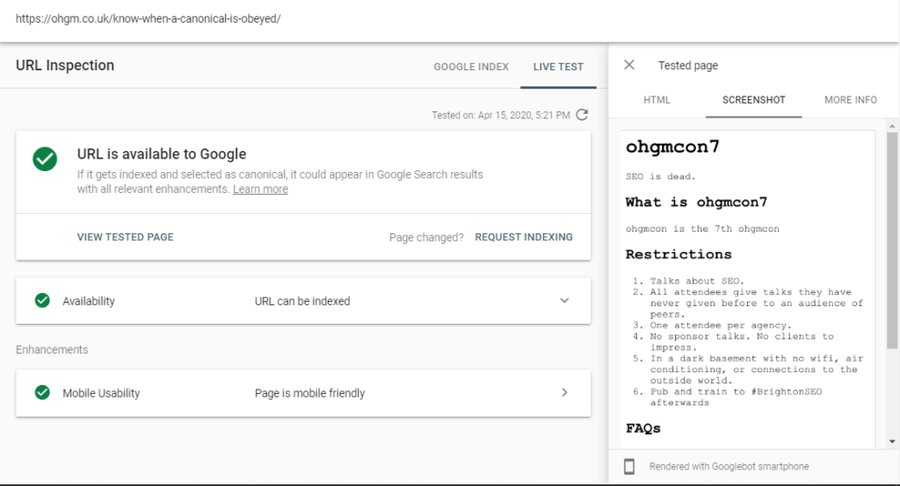
Giving it a few hours, the cache has updated to ‘/con/’:

It shouldn’t take very long for Google to re-index this content and exclude it from the index by canonicalising it across to /con. I’ll update once this is reflected in Search Console also.
That’s all there is to it.
Further Notes
- This doesn’t have to remain on the same domain. You can use this to “migrate” websites with strong ranking signals into completely irrelevant destinations.
Presentation Slides
Here are the presentation slides I had prepared for this:






You might have some questions about that last part. That’s ok.